[머신러닝 프로젝트] 2. 워크 플로우(피드백 추가)
2024. 2. 14. 12:33ㆍ회고/기타 프로젝트

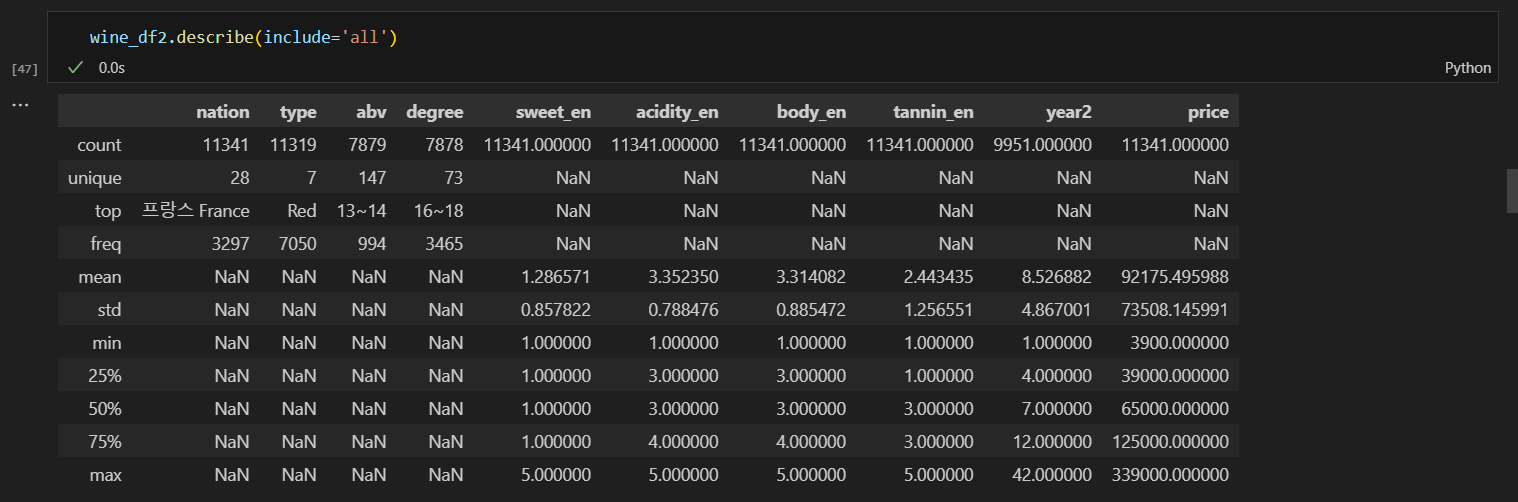
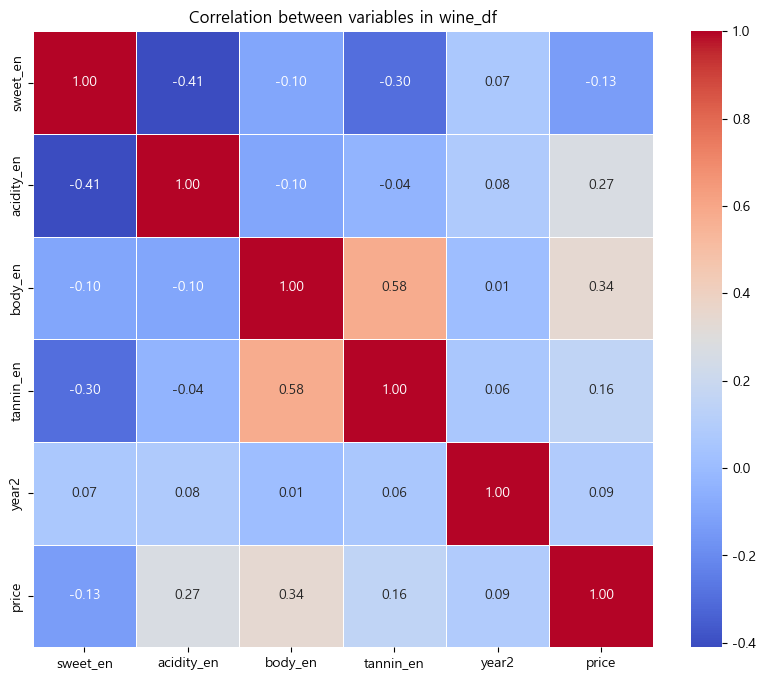
01 수치형 변수로 상관관계 분석













02 범주형 변수(type/year2)








03 피드백_주튜터님
- 추가적으로 할 것: "다중공선성" 체크 -> 다중 선형 회귀가 우선이다.
- 변수를 선택할 때, VIF 10이상인 변수는 드랍해 줌. (좀 더 회귀적)
- 상관계수가 "0.2 ~ 0.3" 이라고 해서 무조건 낮은 수치가 아님.
- 실무에서는 상관관계 트렌드가 있어서 낮다고 무조건적인 수치는 아님.
- 판단 기준에 따라 0.3이면 높다고 보는 경우도 있다는 말이다.
- 현재는 하나의 데이터셋만 가지고 분석하기에 통상적인 해석을 추가하면 좋겠음.
- 일반적인 범주에 대한 설명 추가한다.
- 예를 들어, 일반적으로 수치가 0.n이상이면 높다고 판단한다.
- 상관관계 분석할 때 한 컬럼이 결측치가 있다. 이때 해결 방법은?
- 결측치 비중을 보고 또는 DDL 데이터가 0인지, 결측치를 제거할지, 대체값의 기준을 판단한다.
- 더 정확한 상관관계를 보려면 고민해 볼 사항이다.
- 판단 하고 진행한 후에, 기준에 대한 설명을 추가한다.
- 국가별 scatterplot이 더 직관적으로 보일 것 같다. 하지만 이게 우선 해결 사항은 아님.
1) 다중공선성이란?
- 통계학에서 독립 변수들 간에 강한 선형 상관 관계가 있는 경우 발생하는 문제로, 회귀 분석에서 예측 변수들 간의 상호 의존성으로 인해 모델의 안정성과 신뢰성을 해치는 요소가 될 수 있다.
2) 다중공선성을 체크하는 방법은?
- 상관 행렬 확인: 먼저 변수들 간의 상관 관계를 확인한다. 상관 행렬을 통해 변수들 간의 강한 선형 관계를 시각적으로 파악할 수 있다.
- 분산팽창계수(VIF) 계산: 다중공선성을 확인하는 주요 방법 중 하나는 각 독립 변수의 VIF를 계산하는 것이다.
VIF(Variance Inflation Factor)는 각 독립 변수가 다른 독립 변수들과 얼마나 강하게 상관되어 있는지를 측정한다. 일반적으로 VIF가 10보다 크면 다중공선성이 존재한다고 판단한다.
3) 각 변수의 VIF를 계산하는 방법은?
- 각 독립 변수에 대해 선형 회귀 모델을 적합한다.
- 해당 변수를 제외한 다른 모든 변수들을 사용하여 회귀 모델을 다시 적합한다.
- 이때의 결정 계수(R-squared)를 사용하여 VIF를 계산한다.
- VIF는 1 / (1 - R-squared)로 계산된다.
4) VIF 값 평가
- 계산된 VIF 값들을 평가하여 다중공선성이 있는지 확인한다. 보통 VIF가 10보다 크면 다중공선성이 존재한다고 판단하지만, 실제 결정은 해당 분야의 전문 지식과 함께 고려되어야 한다.
- 다중공선성이 발견되면 변수를 조정하거나 다른 모델을 사용하여 문제를 해결할 수 있다. 일반적으로 다중공선성 문제를 해결하기 위한 방법으로는 변수 선택, 변수 변환, 또는 규제 방법 등이 있다.
5) 사용하는 라이브러리
- VIF 계산을 위해서는 statsmodels 라이브러리의 variance_inflation_factor 함수를 사용한다. 계산된 VIF 값을 확인하여 다중 공선성이 높은 변수들을 식별할 수 있다.
04 피드백_강튜터님
- 다중공선성은 주요하게 나오는 feature serection이 나오면 추가적인 작업을 진행한다.
- = 현재 단계에서 다중공선성은 모델에 영향이 있을 수도 있고, 없을 수도 있기 때문에 변수 둘 다 중요하게 나오면 추가적인 작업을 진행하는 게 맞다.
- = 우선적으로 진행해야하는 부분은 바로, 다중 선형 모델이다.
- 원핫인코딩을 하는 이유는? 머신러닝 모델링할 때 범주형을 바로 넣을 수 없어서 사용한다.
- 원핫인코딩하면 0 또는 1 이진분류법으로 값을 변환해서 변수를 나타내기 때문에 양극단의 값으로 상관관계를 보기는 어렵다.
- 데이터프레임 한 컬럼에 결측치가 있을 때 상관관계를 봐도 되는가?
- 결측값은 제외하고 상관관계를 보여주기 때문에 굳이 안해도 되는 과정이라고 생각한다.
- 21년도를 기준으로 생산일자를 뺀 컬럼(year2) 같은 경우는 범주형 변수로 사용한다.
- 동일한 조건으로 와인을 만들었다면? 수치형 변수가 될 수 있다.
- 카테고리를 나누는 기준은 고민할 부분이다.
- body별 가격분포를 보고자 하여 제작한 현재 히스토그램(블로그에 넣지는 않음)은 body_en별 분포가 나와있지 않고 전체를 합쳐서 나타냈다. 타입별 히스토그램 분포를 보면서 확인하는 게 (모든 타입을 한 그래프에 나타내는 것보다) 보기 좋겠다. 박스플롯 하나당 히스토그램 하나의 값과 같은 것이다.
- boxplot의 아웃라이어를 전부 이상치라고 판단하기는 어렵다. price에 영향을 주는 다양한 요소가 있으니까. 일단은 가격을 나타내는 정도로 이해하면 좋겠다.
05 피드백 수용 후, 시도할 점
- 다중 선형 모델 제작(다음 글로)
- 다중 공선성 체크 시도(다음 글로)
- body 타입별 히스토그램(이건 내가 보고자해서 알려주셨다.)
- body 타입별 평균 가격(내가 봐야할 것 이거였다.)
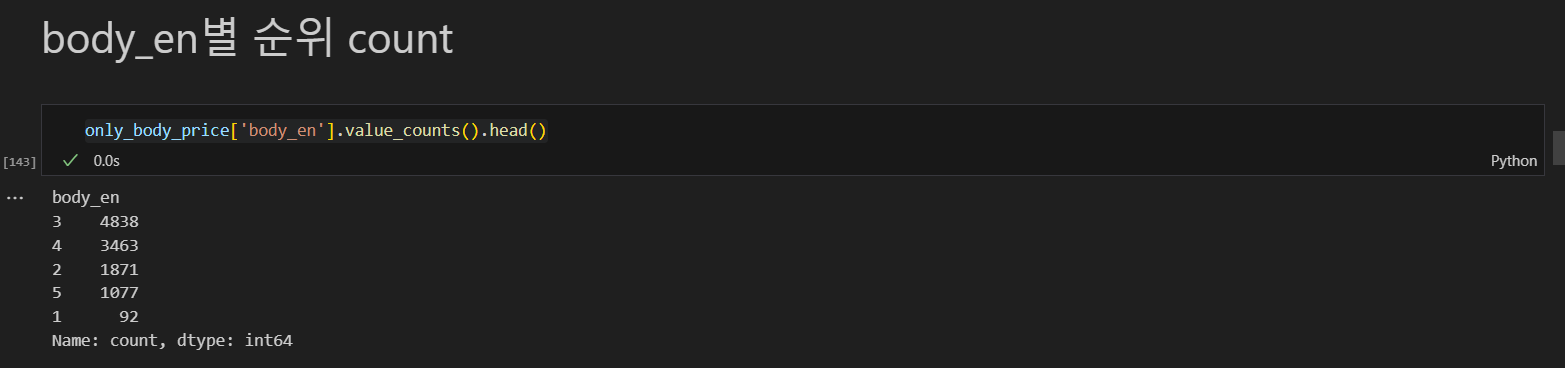
1. body 컬럼별 분포





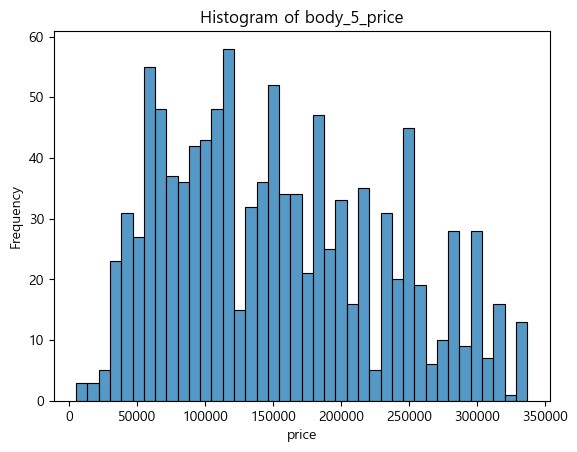


2. body 컬럼별 평균

💡바디감 타입별 평균을 구해보니로 1→5로 갈수록 평균 가격이 올라간다.
'회고 > 기타 프로젝트' 카테고리의 다른 글
| [머신러닝 프로젝트] 4. 데이터 분할, 문자+수치형 컬럼 변환 (0) | 2024.02.16 |
|---|---|
| [머신러닝 프로젝트] 3. 단순/다중회귀모델 결과비교 (0) | 2024.02.14 |
| [머신러닝 프로젝트] 1. 현재 상황(상담 준비 자료) (0) | 2024.02.13 |
| [심화 프로젝트] 준비 - 산점도, 히스토그램 (0) | 2024.02.07 |
| [심화 프로젝트] 준비 - '와인 가격 예측' 주제 선정 (0) | 2024.02.06 |