2024. 4. 4. 12:59ㆍ프로젝트/빵맛집 추천서비스 웹배포

01 문제 해결 과정
1. 추가적으로 더해야 할 데이터를 수집하는 코드를 빨리 짠다.
- 작성자 아이디, 작성일 추가 수집, 리뷰 not in 조건 빼고 수집->정보없음 처리
- 와이파이 이슈로 다른 코드로 대체됐다.
2. 주소 데이터 추가해서 한번에 merge까지 시키기
- 같이 작동할 수 있도록 코드 만들기 > 자동화된 코드의 완성
3. 데이터 적재 시점에 대한 데이터 컬럼 추가
- to_datetime을 이용해서 현재 시간을 추가했다.
4. result = [] 초기화 시점을 잘못 잡아서 pass했더니 결국 문제가 생겼다.
- 첫 리뷰에 텍스트가 없고 '정보'버튼만 있으면 result를 못찾아서 정렬 전으로 재배치했다.
- 드디어 해결!
02 크롤링 작성자, 작성일 드디어 찾았다.

- 세분화 해서 들어가는 메서드 체이닝이 아예 안됨. 상위 먼저 긁었더니 130개가 나왔다.
- 목표가 65개였는데 뜯어보니 작성자 65개*작성내용65개였다.
- 와이파이 이슈로 원래 코드를 수정해서 사용하기로 했다.
03 잘못된 코드 element.tag_name > 2차 경로를 줘야 한다.
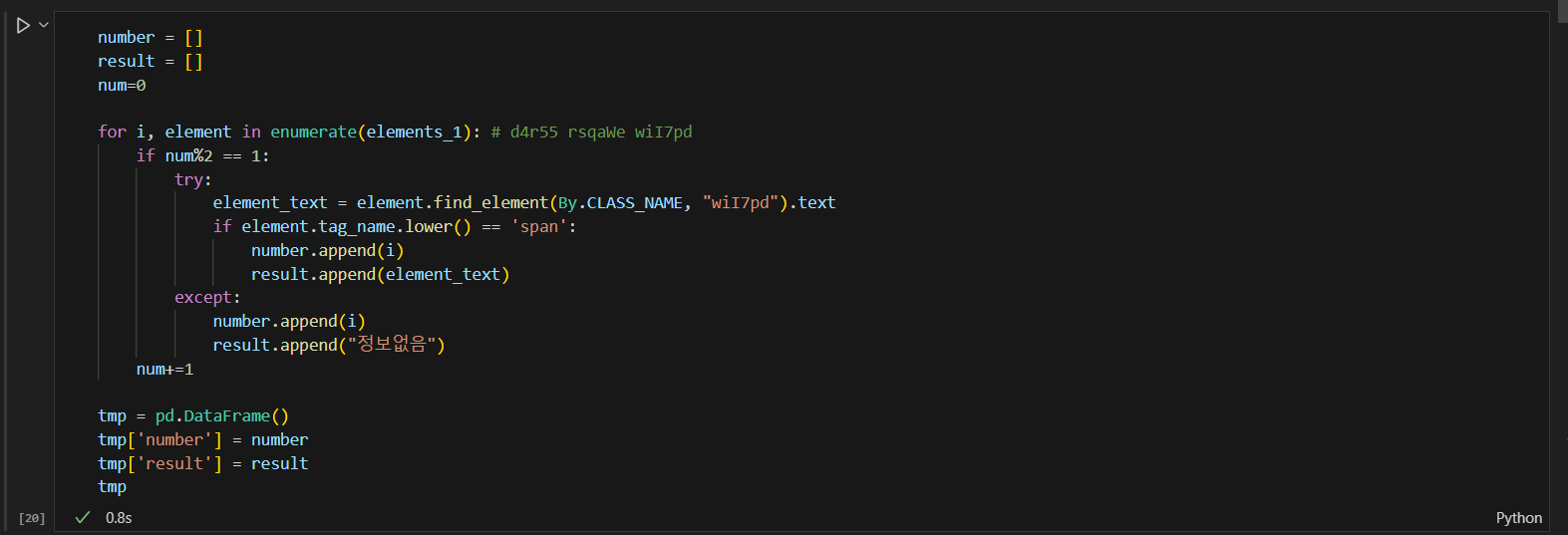
04 이게 왜 0으로 나오는지 뜯어보기 : 해결


- 문제 해결 24번 참고하기: 정렬 전에 result = [] 초기화를 시켜야 했다. 초기화 변수 순서의 문제였다.
05 문제 해결 과정에서의 인사이트
# KT기준 유입인구 지도그래프를 기준으로 순서를 정한다.
https://giraf.sktelecom.com/web/kostat
은평구-서대문구-마포구-성북구-종로구-중구-동대문구-강남구
# 최종컬럼
[Platform] - [Number] - Store - Address - Review_score - Review_counts - [ID] - [Date] - Review_text - Time
# 질문목록 -> ㅅㅎ튜터님 상담 완료(14시~15시)
1. 크롤링 데드라인
2. 요기요 -> 노이즈 데이터가 많아서 하지 않기로 결정했다.
3. 프랜차이즈 제거 -> 플젝이 빵집추천인데 빼기, 클러스터링 하는 의미가 없음, 지역별로 원래 있음, 숨은 맛집을 추천하는 느낌이니까 클러스터링 때는 빼기.
4. 군집화 -> 주소/가게이름/리뷰수/평점수/특성컬럼1~9
5. 종로구 다음은? -> 유동인구 많은 수 기준으로 시작
6. 시군까지 끊기 -> 서울 종로구
7. 차별화 -> 여쭤보기
8. 가게 이름에 공백 없애기
9. 층수 -> 필요 없음. 리뷰를 긁어와서 특징으로 보여주는 건 좋다. 리뷰를 크롤링한다고 했을 때 데이터프레임으로 받고, 가성비, 맛집, 길이 복잡하다, 함수를 만들어서 필터링을 한다, 기본적으로 모두있는 데이터를 기반으로 하는게 맞다. 모두 기재되지 않으면 클러스터링에서 뺀다. 기준을 세울수가 없게 되니까 지리적 위치에 관한거까지만 클러스터링 컬럼으로 만드는 게 낫다. 리뷰를 어떻게 하면 잘 필터링할 지가 요점이다.
10. google_jongro.csv
11. 모델링에 사용될 컬럼 -> 컬럼을 추려나가야하는게 주요과정이다.컬럼 간의 상관계수를 보거나~ -> 일단 다 넣고 뺐을 때 결과가 잘 나왔다면 뺀 이유를 저 근거를 들어, 팀회의를 들어 -> 모델의 적합도?는 모델이 정해주는 것이다 -> 데분가가 이해하는 것과 라이브러리가 판단해서 학습하는 건 다소 차이가 있을 수 있고 이부분을 절충하는 게 클러스터링의 핵심이다. (컬럼이 중요하다 생각했는데 넣고 빼고의 차이가 없다면 제외하고)
12. 아이디, 리뷰: 고유값들 말고 행동특성에 대한 컬럼만 가지고 군집분석을 진행한다. 가장 먼저 해야할 것. 빵집ID, 빵집 이름, 리뷰 날짜, 작성자ID 제거해야 한다.
# 컨셉을 잡아보자 -> 13시30분 팀회의
- 챗봇 팔이 사업계획서 pt느낌
- 접근성 컬럼 추가 : 경사도, 주차, 뚜벅이, 층수
- 우리 챗봇의 차별화 파트 어필
# 3시부터 크롤링?
# '//div[1]/div/div' 이게 왜 이거만 되는 거야? -> 결국 스크롤 다 내리고 클래스 네임만 했더니 됨.
# 대기 시간만 충분하면 리뷰도 중복 체크할 필요가 없을 것 같은데?
- 쁘티통 리뷰 48개 (조그마한 빵집으로 끝난다.) 업체 답변 빼고 44개가 나와야 한다.
- 쁘티통 작성자 65명
- 쁘티통 작성일 65개
- 65=65이라는 규칙 발견, 각각의 elements라서 try가 안될 것 같아서 인덱스 번호를 이용하기로 함. 안됨.
- 안됨. 65개에서 48개로 그리고 44개로 줄여야 된다. 처음 인덱스를 맞춰야 한다.
- 됐다! > 리뷰수가 자꾸 줄어든다. > 로딩의 문제? -> 와이파이, 인터넷의 문제였다.
# ㅊㅂ튜터님 상담
- 프렌차이즈 빵집 : 제거, 굳이 추천하지 않아도 알고 있으니까
- 클러스터링 컬럼 : 우리가 쓸 수 있는 컬럼이 뭐가 있을지 파악하는게 먼저다.
[!] 데이터 쌓을 때 적재 시점을 추가해야 한다.
- 종로구 빵집의 넘버링 좋다.
[!] 다음 페이지 넘어가는데 걸리는 시간이 있으니까 클릭한 시간을 적음.
- 데이트, 리뷰카운트, 아이디 이런거 필요 없다. 리뷰에서 유의미한 내용을 뽑아야 한다.
- 압사 : 키워드 자체를 미리 정해주지 않으면 미쳐서 날뛴다.
- 압사 : https://monkeylearn.com/blog/aspect-based-sentiment-analysis/
- 네이버 리뷰 키워드를 좀 수정할 필요는 있지만 아이디어는 좋다.
- 본인이 빵집 갔을 때의 프로세스를 녹인다.
- 페르소나를 만들어서 이 사람들이 어떤 정보를 원할까 생각해보면 클러스터링 컬럼이 뽑힌다.
- 압사로 점수를 뽑아내면 행이 스토어, 컬럼은 친절해요 몇점, 분위기 몇점 이렇게 한다.
- 저라면 차원축소(pca, als...)할 것 같다.
- 식상하지만 괜찮다고 생각하는거는 시장을 지배하는 게 없다.
- 계속해서 나오는 이유는 니즈가 있..으니까.. 잘하면 잘해야 좋겠다..
- 해봤다가 ㅌㅌ
- 참고 : https://disquiet.io/product/%EB%8C%80%EB%8F%99%EB%B9%B5%EC%A7%80%EB%8F%84
- 기획 자체가 좋지 않고, 빠르게 비즈니스 모델을 유입하려고 했음.
- 고객에게 전달되는 유용함이 있어야 하는데, 빵집에게 정보를 손쉽게 받으려고..
- 유저가 필요로 하는 게 뭘지 잘 파악했으면 좋겠다.
- 가중치: 라이브러리보다 방법론을 먼저 찾고, 피쳐 엔지니어로 찾는게 맞지 않나.
- 간단하게 두개를 넣는다.
- 돈을 투자할 수 있다면? 키워드 추출은 gpt를 이용한다.
- ABCD 연관도를 점수로, json형태로 반환해 줘.
- 영어로하면 더 싸다.
- 자연어처리 몰라도 할 수 있다.
- 잘나오나요? 물어보면 생각보다 잘 나온다.
- 특성에 따라 점수를 뽑아냈으니까 다음은 여러 다양한 방법이 있겠다.
- 리뷰가 빵이 맛있었어요에 대한 점수를 100점 만점으로 나온다.
- 젬마 대신 클로드
- 긍부정 전문은 아닌데 어느정도는 한다.
- 지금까지 알려준거 다 전문은 아니고 어느정도 한다.
- 클로드도 유료
- 지피티 3.5면 충분한데 얜 좀 저렴하다.
- 몇십개 돌려보고 지피티, 클로드 중에 골라보면 되겠다.
- 애자일: 민첩하다, 데이터가 뭐가 민첩하냐, 지피티 결정했어 했는데 별로면 다시 해야되잖아.
- 5만개 중에 100개정도 해보고 빨리 돌아가는 방법이다.
- 샘플테스트도 애자일한 방법 중에 하나이다.
- 챗봇이요? 혹시 라그RAG라고 아시나요?
- 굳이? 싶은, 성능이 안좋음, 돈은 돈대로 나가고, 별로임
- 지금 약간 불완전 해보이는 건 서비스 형태가 ui가 안잡힌다
- 유저가 들어갔을 때 뭐가 보이는지? "기획"의 문제. 안보인다.
- 실제로 회사에서 실제 통계자료보다 실제 비즈니스 기획력이 중요할 때 있잖아.
- 이미 많이 기획력이 들어간 프로젝트로 보인다. 분석100퍼 보다.
- 클로드, GPT3.5, 4.0, Solar(현재 무료)
- 감 안잡히면 > 페르소나가 중요한 이유 여기서부터 시작한다.
- 이걸 잡아야 유저 인터뷰도하고 설문 조사도 시작하고 (기업에선 이렇게 함,)
- 빵 이름이 있다면 실제로 굉장한 신호이다.
- 리뷰를 수십개를 던질 때마다 빵이름 뽑아줘 (랜덤 샘플링, 스트리트 샘플링) 100번? 매번 다른 빵이름 뱉잖아. 이걸 정렬하고? 반복을 시키는 과정이 필요하다? 이런식으로 회사에서도 한다.
# ㅎㅅ튜터님 주제 상담
# 애견, 세분화 이런게 정말 많이 시도하고 실패하는 경우다.
- 데이터가 많이 없다. 첫 번째 방식으로 해보는 게 어떤지?
- 어떻게 매력적으로 풀건가? 성능이 얼마나 좋은지가 중요한 거 아닐까?
- 일단 아웃풋(성능)이 나와야 알 수 있겠다.
- if 데이터기획자, 사업기획서 느낌으로~ 그렇게 설명하는 것도 매력적인 방법이긴 하다.
- 혹여나 그 과정도 어려움..이 있다면 결과가 별로 안나온다면..?ㅠ
- 결과가 만족스럽지 않았어도 가치가 있다고 녹여내면 가치가 있겠다.
# 하나만 잘해봤으면 좋겠다고 얘기하는 것은?
- 기획서 이런게 없이 성능이 중요할 것 같은데 기획서가 있고 폼이 잘 만들어 진다면 나쁘지 않음.
# 여태 별로였던 이유는 기능이 별로였다.
- output이 안좋았기 때문이다. 좋으면 된다!ㅋㅋ
# 요소가 안뜨는 건 와이파이의 문제, 성능업, 랜선 꽂아서 돌리기
# merge까지 해서 전달하기!!
- 프랜차이즈 제거 (전처리 부분)
- 적재 시점 마지막에 추가하기 (크롤링 부분)
# 적재 시점 추가하기 코드
from datetime import datetime
time_list = []
now = datetime.now().strftime('%Y-%m-%d - %H:%M:%S')
time_list.append(now)
# 은평구 60분 정도, 서대문구 nn분 기록 중
# 초기화 변수 위치 차이를 이해해야 한다.
- 리뷰가 아예 없으면 정보가 눌려서 result = 갱신이 되지 않아 = 전 가게꺼 나옴.
- 리뷰가 있어서 정렬이 눌려 하지만 별점만 있다면 갱신이 되어 리스트는 0이 나올 수 있음.
- 처음부터 리뷰가 없는 가게가 나온다면? result 자체가 없어서 에러가 뜬다.
(결론: 모든 문제를 해결하기 위해서 result 초기화를 정렬 전에 배치한다.)
'프로젝트 > 빵맛집 추천서비스 웹배포' 카테고리의 다른 글
| 04.06 종로구에서 크롤링 하다가 멈췄다. (feat.map,filter) (0) | 2024.04.06 |
|---|---|
| 04.05 크롤링 '자세히' 클릭 코드 추가 및 기타 진행 사항 (0) | 2024.04.05 |
| 04.03 전처리, 크롤링 문제 해결 과정 (0) | 2024.04.03 |
| 04.02 전처리 문제 해결 과정 (0) | 2024.04.02 |
| 04.01 크롤링 문제 해결 과정 - 1차 수집 완료 (0) | 2024.04.02 |