2024. 4. 18. 22:11ㆍ프로젝트/빵맛집 추천서비스 웹배포

01 엘보우 포인트 기준 "군집수=19, 난수=0" 에서 시작한다.


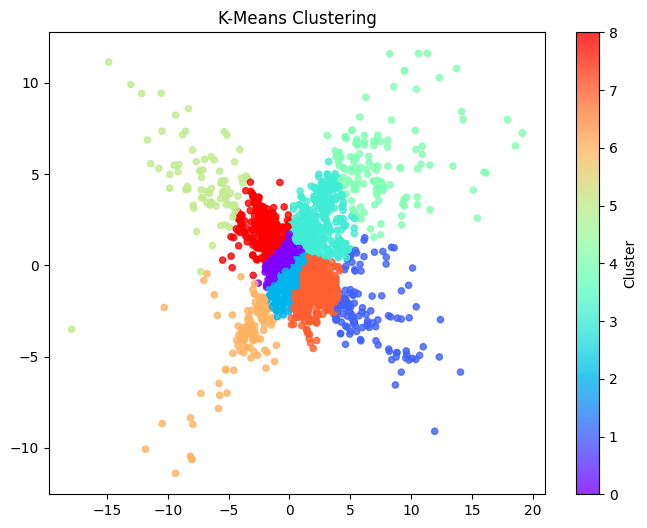

02 이너샤 기준 "K=8"로 시작한다.








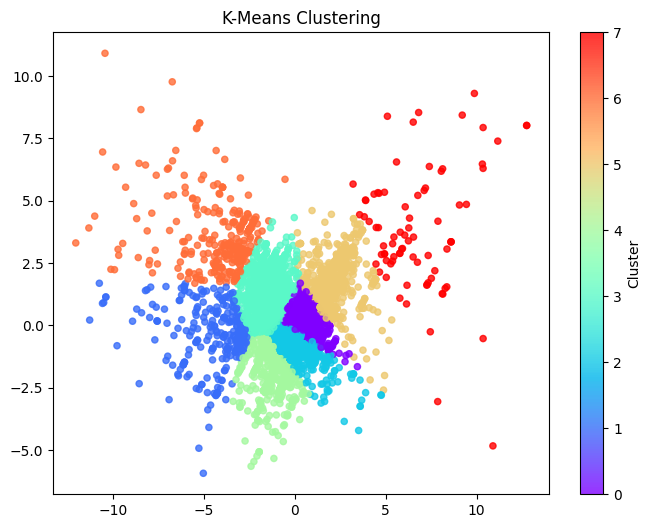

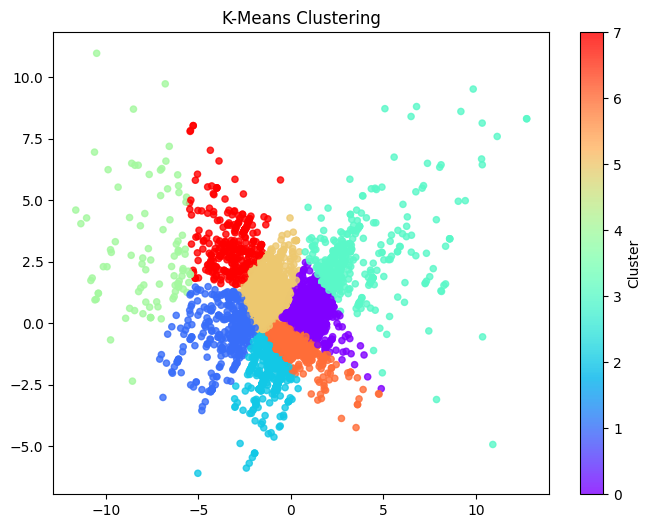

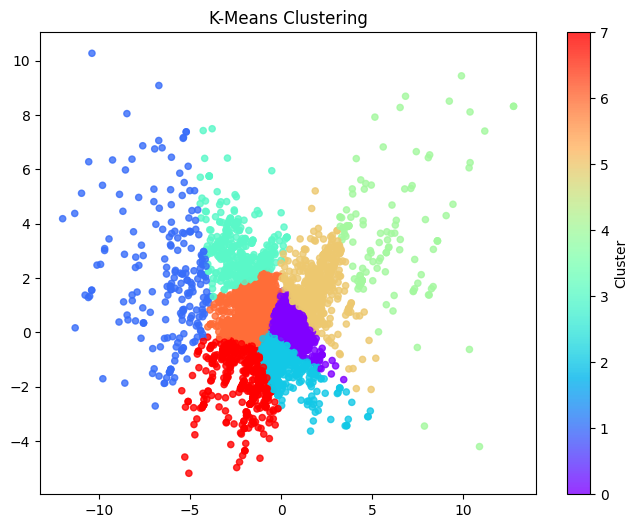

03 실루엣계수 기준 "K=6"부터 시작한다.


04 군집수 참고자료


05 클러스터링 피드백 모음
1. 전담 튜터님: 차원축소만 하는 방향
# 군집화 설명
- pca의 단점은 뭘 설명하는지 모른 다는 것이다.
- 각각의 계수들을 보고 의미를 만들어 낼 수 있으면 만드는데 고차원은 어려움.
- 7개의 클러스터가 나왔으니 각각 데이터셋에 라벨링을 다 해주시고
- 가게당 하나, 라벨 하나를 붙일 때 하드클러스터라고 한다.
- 우리는 소프트 클러스터 -> 하드 클러스터
- 기준이 되는 데이터를 정하고 이게 군집이 잘됐는지 판악: 도메인 지식이 중요하다.
# 클러스터링 판단 기준
1. 지표: 초깃값 세팅할 때 유용하고 (보통 실루엣이나 kmeans는 엘보포인트 체크)
2. 군집 내 데이터 간의 이질감
3. 군집에 속하는 데이터들의 개수가 너무 편향되지는 않는지
# 실무에 가면 "데이터 분석은 노가다다."라는 말이 있다.
2. 게임 도메인의 튜터님: pcaplot에 대해 설명해주셨다.
# 스크리 도표 : 전체 컬럼이 들어가고,
- 차원축소 : 2차원으로 보세요.
- 컬럼A의 100값과 컬럼B의 100값이 다르다.
- 2차원이 가시성이 높다.
- just 군집개수, 컬럼을 선정해주면 된다.
- 군집개수를 구하려고 스크리 하는거고,
- 이걸 시각화하기 위해서 pcaplot을 보게되는데 2차원으로 보면 된다.
# 정리
1. 대충 스크리값 보고 4개 군집으로 나눠라고 참고만 해.
2. 정답이라고는 생각 안해.
3. 일단 모든 컬럼을 다 가져간다.
4. 리뷰점수는 "표준화"가 필요없을거 같다.
# 중요
- 차원축소=컬럼을 한번에 보겠다.
- 축소가 잘됐는지 봐야겠죠?
- 차원축소 한걸 2차원으로 볼래 하면 pcaplot이 나온다.
- 각각의 컬럼이 따로 놀고 있으니 한번에 보는 것이다.
# 차원이란 말에서 벗어나라!
- 각각의 컬럼의 다 넣고, 특징을 파악을 하는 거다.
- 차원축소=컬럼이 여러개 있는데 따로 있으니까 하나의 그래프로 보고 싶어서하는 것이다.
- 하나빼고 pcaplot 그려보고 잘 구분되어 떨어질 때까지 하면 된다.
- 컬럼축소=차원축소 라고 이해해라!
- 합친 게 아니라 2차원으로 보겠다. xyz가 아니라 xy로 보겠다.
# 처음해봐서 어려우면
- n컨퍼넌트에 "1"을 넣고 확인해보면 된다.
- 차원? 버려.
# 컬럼 표준화할 필요가 없다?
- 표준화 방법에 대해 차후 질문했다.
정리: 직접해보니까 어떤 말을 하고 싶으셨는지 이해했다. 컬럼을 제거하는 방법에는 직접 제거와 차원 축소가 있는데, 정리된 컬럼이 여러개고 고차원은 시각화에 어려움이 있으니 pca를 통해 2차원으로 보겠다 선언하고 시각화의 용도로 사용할 수 있는 것이다.
3. 이어서 튜터님: 특성컬럼 표준화, K값을 선정하는 고민
# 특성컬럼 표준화
1. 특성컬럼: 표준화 하고 진행 vs 표준화 안하고 진행 비교 필요하다!
2. 리뷰수, 평점: minmax 스케일러 사용보다는 스탠다드 스케일러 사용이 좋다. minmax는 최소 0 최대 1 이라, 최대값이 20000 인 경우 이친구가 1이 되고, 나머지값은 0 에 수렴하여 이상치 처리에 약하다! 따라서 평균을 0으로 만들어주는 스탠다스 스케일러 사용해서 진행해주세요.
3. 긍부정지수: 표준화 필요 없습니다!
- 민맥스는 2만이 1로 잡히면 나머지 거의 0에 수렴해서 우리 데이터에는 쓰면 안된다.
- 로버스트는 밀도가 엄청 낮다. 이상치에는 낮으나(?) 데이터간의 거리감이 엄청 멀어지는 스케일러다. 분산이 높으면 클러스터가 어렵다. 군집화는 거리로 하는데 거리가 너무 멀면 -> 군집화가 힘들다. 그래서 절충한게 스탠다드 스케일러다.
# 군집의 수
- 4,8이면 4,6,7,8을 봐야한다. 중요도를 따지면 그래프를 그린게 훨씬 중요하다.
- 실루엣은 정말 참고치여서 이건 얼마든지. 실루엣도 그래프를 그릴 수 있다.
- 실루엣은 밀도를 기반으로 클러스터링을 돌리는 하나의 계산식이다.
- 그래서 데이터가 많으면 정확도가 떨어지고, 너무 단순하긴 해도 점수가 나오니까.
- '-1'~'1'사이의 값을 가지고 1에 가까울수록 잘 군집이 됐다. 0에 가까울 수록 근처 군집과 겹친다.
- 실루엣 인덱스를 보게되면 저 친구들은 겹치는 게 많다.
- 이건 다 0.2대로 떨어진다. = 겹쳐있다고 보는 것이다. 어디까지나 참고치로만 봐라.
- 데이터가 많으면 거리를 계속 계산해야 하기 때문에 정확도가 많이 떨어진다.
- 클러스터가 1이면 응집도1 근데 이걸 억지로 쪼개려다보니까 클러스터가 싫어함. 정확도가 떨어진다.
- 참고: python distance map clustering = 군집이 얼마나 겹쳐져 있는지만, 계속 달라짐, 그래서 참고만
- 실루엣도 그렇게 참고만 한다.
- 우리는 엘보메소드를 사용해서 (참고로) 봐주면 된다.
- 엘보를 보고 혹시 실루엣 계수가 어떨까?하고 참고하는 정도로만
- 우리는 항상 pcaplot을 계속 확인하는 것이 중요하다. (가장 중요)
# 이상치
- 말도 안되는 값이거나 안찍혀 있는게 이상치이다.
- 0값은 그냥 값이 없는거다. 이상치 아니다.
- 대신 답이 텅텅 비어있으면 처리 해주셔야겠죵?
- 파이썬이 업그레이드되면 먹통이 되는 경우가 있다.
- 사이킷런이 예민한 친구이긴 하지만 파이썬 자체가 예민하다.
4. 다른 튜터님: 데이터 개수 관련
- 데이터의 개수는 2~3만개 정도면 충분할 것 같다. (수준별 튜터님도 1만5천 충분하다고 하심!)
- 이 프로젝트에 30만원 이상을 투자할만한 가치가 있는지는 모르겠다.
- 한 개의 ‘구’를 선택해서 진행해보되 발표 때는 비용적인 문제로 한 개 구만을 선택하게 되었다고 설명해봐라
- 일단 버전별, 데이터 개수별 비용을 산정해보고 판단해봐라.
06 문제 해결
- 팀원마다 실루엣계수가 달려져서 사이킷런 버전을 확인하니 1.2/1.3/1.4였다. 해결했다.
07 군집수 참고지표👍
1) kelbow_visualizer, inertias, 그리고 실루엣 계수는 서로 다른 개념이다. 각각 K-means 클러스터링에서 최적의 클러스터 수(K)를 결정하는 데 사용되는 지표들이지만, 그 작동 방식과 제공하는 정보의 종류가 다르다.
2) kelbow_visualizer와 inertias
kelbow_visualizer와 inertias는 K-means 클러스터링에서 클러스터의 수(K)를 결정할 때 사용되는 방법 중 하나인 'elbow method'를 시각화하거나 계산하는 데 사용된다. 여기서 inertias는 클러스터 내 분산의 합을 의미하며, K의 값이 증가함에 따라 일반적으로 감소하는 경향을 보인다. 'elbow method'는 이 inertias 값의 변화를 그래프로 나타내고, 그래프의 '팔꿈치'처럼 꺾이는 지점을 최적의 클러스터 수로 간주하는 방법이다. kelbow_visualizer는 이 과정을 시각화하여 사용자가 쉽게 '팔꿈치' 지점을 찾을 수 있게 도와준다.
3) 실루엣 계수
반면, 실루엣 계수는 클러스터링의 품질을 평가하는 데 사용되는 다른 지표이다. 실루엣 계수는 -1에서 1 사이의 값을 가지며, 클러스터 내의 데이터 포인트가 얼마나 잘 그룹화되어 있는지, 그리고 다른 클러스터와 얼마나 잘 분리되어 있는지를 나타낸다. 실루엣 계수가 1에 가까울수록 클러스터 내의 데이터 포인트가 서로 가깝고 다른 클러스터와 잘 분리되어 있다는 의미이다. 실루엣 계수를 사용하여 다양한 K 값에 대한 클러스터링 품질을 평가하고, 가장 높은 실루엣 계수를 가진 K 값을 최적의 클러스터 수로 선택할 수 있다.
5) 즉, kelbow_visualizer와 inertias는 클러스터 수(K)를 결정하기 위해 클러스터 내 분산의 변화를 분석하는 반면, 실루엣 계수는 클러스터링 결과의 품질을 평가하는 데 사용되는 지표이다. 따라서 이 두 방법은 서로 보완적으로 사용될 수 있으며, 최적의 클러스터 수를 결정하는 데 도움을 줄 수 있다.
6) 튜터님이 "K가 증가함에 따라 군집 간의 센트로이드가 다른 군집과 거리가 멀어야 한다. 그걸 얘가 보여준다."라고 했는데 실루엣 계수가 이러한 값을 보여준다고 생각한다.
08 프로젝트 참고링크
약속장소, 맛집 추천 서비스
https://acornedu.co.kr/lms/upload/project/2022/3/MachineLearning_22_02.pdf
✏️ 깨달은 점
군집수로 참고 할 수 있는 엘보우 포인트, 이너샤, 실루엣 계수 등을 확인하고 어떤 K를 어떻게 설정해야할지 전체적인 그림을 맞춰보는 시간이었다. 라벨링을 하고나서 군집이 잘 이루어졌는지, 우리가 군집을 잘 설명할 수 있을지 확인하는 과정을 내일 해봐야겠다.
'프로젝트 > 빵맛집 추천서비스 웹배포' 카테고리의 다른 글
| 04.20 군집화 마무리 -> ux/ui관점 회의 -> streamlit 공부 (0) | 2024.04.20 |
|---|---|
| 04.19 클러스터링에 대한 해답을 찾아가다. (0) | 2024.04.19 |
| 04.17 K-means++ clustering, 데이터 클렌징은 계속 된다. (0) | 2024.04.17 |
| 04.16 프롬프트 활용한 파생변수 완성 -> 전처리 (0) | 2024.04.17 |
| 04.15 최종 프롬프트 완성 후 api활용 파생변수 생성 시작 (0) | 2024.04.15 |