2023. 12. 14. 17:14ㆍ회고/TIL(매일)

도전한 점
- 데이터분석 2주차 강의
- 데이터분석 아티클 스터디 4일차
- python : 모든 내용을 절대 외우려고 하지 말 자주 사용하며 체득하는 것이 중요하다.
- 구글링 : 정보학 시작하자마자 배우는 것, 검색 원숭이란 단어가 잊히지 않는다😂
- 분류, 목록, 색인 : 도서 내용을 정확하게 파악하기 위해 정해진 분류표에 의해 나누는 것이 분류(clssify)이고, 이용자에겐 자료검색의 도구이며 관리자에겐 업무수행에 도움을 주는 도구가 목록(cataloging)이다.
- 분류는 나눌 分, 무리 類. 목록은 제목 目, 기록할 錄.
- 일반적인 cataloging 이란 품목과 내용을 일목요연하게 기록한 것 = list 을 의미한다.
- Colab
- 오늘 배울 내용 : 변수, [리스트], 인덱스, {딕셔너리}
- 변수 : 컬럼이라고 생각함. 데이터를 넣어둔 서랍이나 상자의 이미지
- 하나의 변수에 여러가지 데이터를 넣을 수도 있다. 1:n이 가능하다.
- 그럼 여기 들어갈 여러가지 데이터를 어떻게 '분류'할 것인가가 중요하다.
- 데이터를 분류하는 방법에 따라 나뉜다 : 리스트, 딕셔너리
- 리스트 : 순서대로 담은 데이터 목록 자체를 변수에 넣는 것. 인덱스를 활용하여 출력할 수 있다.
- 목적 : 여러 가지 값을 한 번에 저장하고 싶다.

*나는 리스트를 한번 묶어줬는데 그냥 대괄호만으로도 가능하다. 똑똑하군.
*리스트라는 포장을 여는 역할은 [대괄호]로 시작한다고 생각하자. 간편함.
*인덱스 출력은 0부터 시작한다.
*리스트 안에 리스트를 담을 수 있다.
- 딕셔너리 : 각각 이름표를 하나씩 붙여서 구별한다. key에 따른(:) value값으로 구분된다.
- 목적 : 여러가지 값을 한 번에 저장하고 싶다. (리스트와 같음)

- 복습하기

- pandas : 싸이클에서 데이터 클렌징(기본 세팅)와 분석을 한 번에 끝낼 수 있다.
- 진행 방법 : 사용 선언 > 데이터 가져오기 > 확인 및 표읽기 > 공백란 제거하기 > 분석

- 구글 스프레드시트로 진행했던 분석을 python으로 간단하게 끝내기
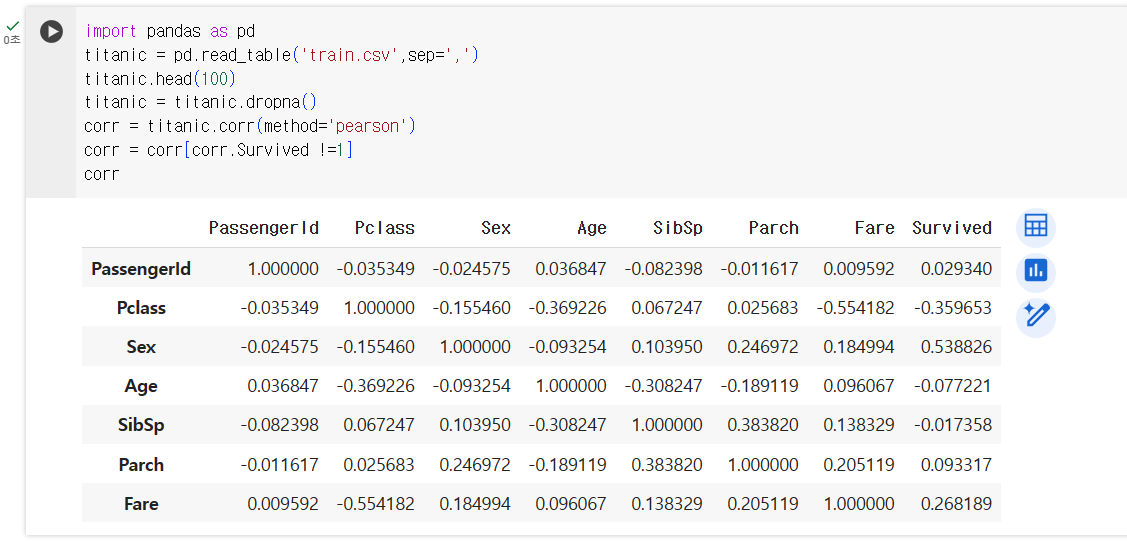
- phthon + pandas 코드 분석
import pandas as pd -> pandas 사용선언
titanic = pd.read_table('train.csv',sep=',') -> 파일 불러오기
titanic.head(100) -> 데이터 파악
print(titanic.isnull().sum()) -> NULL데이터 파악
titanic = titanic.dropna() -> 공백란 제거
print(titanic.isnull().sum()) -> 결과확인
corr = titanic.corr(method='pearson') -> 상관계수 구하기
corr = corr[corr.Survived !=1] -> 상관계수 1요소 제거
corr -> 결과확인
- matplotlib
- phthon + matplotlib 코드 분석 (이어서)
import matplotlib.pyplot as plt -> 사용 선언
corr.plot() -> 모든 요소 포함한 그래프 출력 -> 삭제
corr['Survived'].plot() -> 생존률만 남기고 출력 -> 삭제
corr = corr.drop(['PassengerId'], axis ='rows') -> 필요 없는 데이터 삭제
corr['Survived'].plot() 생존률만 남기고 출력 -> 삭제
corr['Survived'].plot.bar() 바형태로 출력 -> 남김
plt.xticks(rotation=45) x축 레이블 45도 회전
*corr 출력 구문은 꼭 삭제 후 업데이트 해줘야 최신 구문의 그래프가 제대로 뜬다.
- 결과 확인


- numpy : 데이터 연산 라이브러리(=코드 모음집)
- seaborn : (주로 랜덤 분포 데이터) 시각화 라이브러리
*생존률 그래프로는 알 수 없었던 인사이트 발견하는 것의 중요성 : 가설 설정이 중요한 이유
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns -> 사용 선언
titanic = pd.read_table('train.csv',sep=',') -> 데이터 불러오기
titanic.head() -> 데이터 확인
print(titanic.isnull().sum()) -> null(공란) 몇개
titanic = titanic.dropna() -> null값 제거
titanic.describe() -> 데이터 통계치 요약
titanic['Age'].hist(bins=40,figsize=(18,8),grid=True) -> 나이에 대한 분포도 그래프
titanic['Age_cat'] = pd.cut(titanic['Age'],bins=[0,3,7,15,30,60,100],include_lowest=True,labels=['baby','children','teenage','young','adult','old']) -> 나이별 구분, 나이별 생존율
titanic.groupby('Age_cat').mean() -> Age_cat을 주축으로 평균값을 구하라
plt.figure(figsize=(14,5)) -> 그래프 크기
sns.barplot(x='Age_cat',y='Survived',data=titanic) -> 바그래프 그리기
plt.show() -> 그래프 나타내기
*hist : hist() 함수를 통해서 히스토그램을 그릴 수 있다. 추이를 볼 때 이용한다.
*groupby : 원하는 컬럼을 기준으로 그룹을 묶을 수 있도록 만들어주는 함수
*mean() : 평균 값을 구하는 함수
- titanic['Age_cat'] = pd.cut(titanic['Age'],bins=[0,3,7,15,30,60,100],include_lowest=True,labels=['baby','children','teenage','young','adult','old']) : 'Age'에서 0~3, 3~7, 7~15, 15~30, 30~60, 60~100을 기준으로 'baby' 이하 별칭으로 라벨링을 하겠다.
- 과제 1. 파이썬으로 당뇨병 상관 관계 분석하기
import pandas as pd
diabetes = pd.read_table('(코랩)diabetes.csv',sep=',')
diabetes.head()
print(diabetes.isnull().sum())
corr = diabetes.corr(method='pearson')
corr = corr[corr.Outcome !=1]
import matplotlib.pyplot as plt
corr['Outcome'].plot.bar()
plt.xticks(rotation=45)
*결론 : Clucose가 당뇨병에 가장 많은 영향을 미친다.

*기타 : 통계치 분석도 해보았다. diabetes.describe()
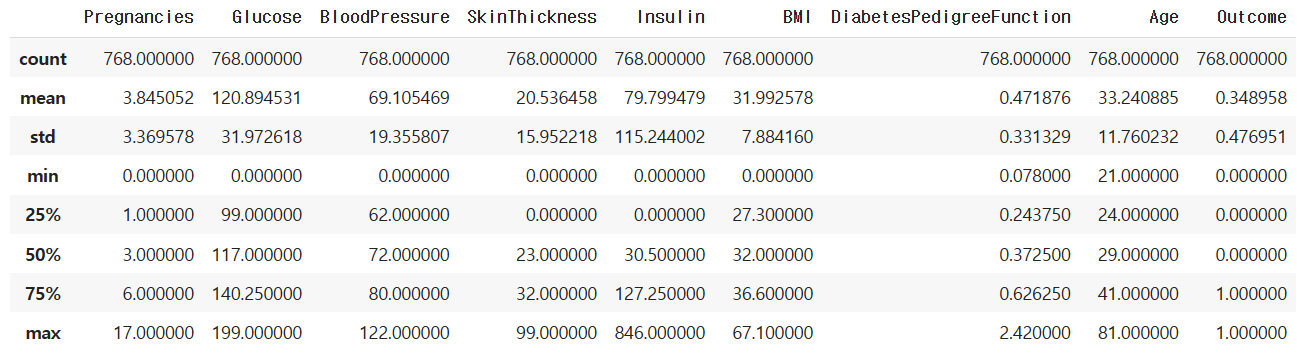
- count : Age 데이터 값은 768개
- mean : 평균 값은 33세
- std : 표준 편차는 11세 (데이터가 얼마나 다양하거나 or 모여있는지 지표이다. 평균에 가까우면 str가 작으며 데이터가 모여있다. 반대로, 평균에서 멀면 str가 크고 데이터가 흩어져 있다.)
- min : 최소 값은 21세
- 50% : 전체의 절반에 있는 사람이 29세
- max : 최대 값은 81세
좋았던 점
- 정리하다가 데이터 한번 날렸는데 복습하니까 정확히 눈에 들어와서 오히려 좋아
아쉬운 점
잊지말 점
- 모든 걸 외우려는 사고 방식에서 벗어나서 자주 사용하며 손에 익히는 것이 중요하다.
- (=), (:) 구분
시도할 점
- 데이터분석 3주차 강의 듣기
- 파이썬 한걸음 더 정리하기
'회고 > TIL(매일)' 카테고리의 다른 글
| TIL 13일차 : 코드카타, 미니 프로젝트 시작 (0) | 2023.12.18 |
|---|---|
| TIL 12일차 : 실전 데이터 분석 (3주차~5주차) (0) | 2023.12.15 |
| TIL 10일차 : correlation (0) | 2023.12.13 |
| TIL 9일차 : null, coalesce, Pivot, rank, 누적합, date_format (0) | 2023.12.12 |
| TIL 8일차 : 복습, subquery, join (0) | 2023.12.11 |