2023. 12. 12. 20:46ㆍ회고/TIL(매일)

도전한 점
- SQL 5주차 : 예상치 못한 상황에 대처하는 방법, 피벗 테이블과 SQL, 업무시간 단축 방법
[1] 테이블이 제대로 된 값을 가지고 있지 않을 때 : 숫자열에 문자가 들어있거나 or JOIN시 값이 없을 때
- 방법 1. [제외] 없는 값은 제외한다 : if ~ null, where ~ is not nall(데이터가 있는거만 불러와)
- Mysql 에서는 사용할 수 없는 값이면 '0'으로 간주해서 일괄적으로 계산해버린다.
- ex) avg(if(rating<>'Not given', rating, null)) : Not given이 아니면 rating값 그대로 써라
- ex) where b.customer_id is not null : 테이블b의 해당 컬럼은 '데이터가 없지' 않다=꽉 채워라
- 방법 2. [대체] 다른 값 대신 사용한다 : if문으로 대체값 주기, coalesce(컬럼, 대체값)
1) 다른 값이 있을 때 : 조건문 이용한다. 예를 들어, if(rating>=2, rating, 대체값)
2) null 값일 때 : coalesce(컬럼a, 대체값b) - 컬럼a에 값이 없을 때 대체값b를 넣어라는 의미
[2] 비상식적인 데이터 값이 조회될 때 : 주문 고객의 나이, 결제 일자 등이 상식 범위를 넘어섰을 때
- 방법 : 조건문으로 값의 범위를 지정한다.
select name,
age,
case when age<15 then 15
when age>=80 then 80
else age end re_age
from customers
[3] SQL로 Pivot Table 만들기
- 왜 엑셀이 아니라 SQL문을 이용해야 하는지? 프로세스 줄일 때 활용하면 좋다
- Pivot table : 2개 이상의 기준으로 데이터를 집계할 때, 보기 쉽게 배열하여 보여주는 것.
- 실습 1. 음식점별 시간별 주문건수 Pivot table 뷰 만들기 (15시~20시 사이, 20시 주문건수 기준 내림차순)
1) 베이스 데이터 만들기
2) 베이스 데이터를 이용해서 Pivot 뷰 만들기

*서브쿼리문에서 결제시간 이라는 테이블을 만들었으니 메인쿼리문에 작은따옴표는 생략한다.
- max 함수를 이용한 Pivot table -> 왜 max를 꼭 써야하지? : 실습 2-1을 보면 이유가 나옴. 궁금증 해결.

- max 를 생략하고 if 함수만을 사용한 Pivot table -> 안나옴.

- 실습 2. 성별, 연령별 주문건수 Pivot table 뷰 만들기 (나이는 10~59세 사이, 연령 순으로 내림차순)
*메인 쿼리문

*결과

*MAX나 SUM 같이 연산식과 필연적으로 같이 쓰는 것이 GROUP BY이다. 외워두기.
- 실습 2-1. 성별을 기준으로 연령별 주문 건수 Pivot table을 만든다면 어떨까?
[1] age_group 연령대 테이블 그대로 쓰기 : 문제 없는데 너무 길다.
*메인 쿼리문

*서브 쿼리문 : max를 쓸 수 있는 이유가 '10대'이면서 'male'의 유일값이기 때문이다.
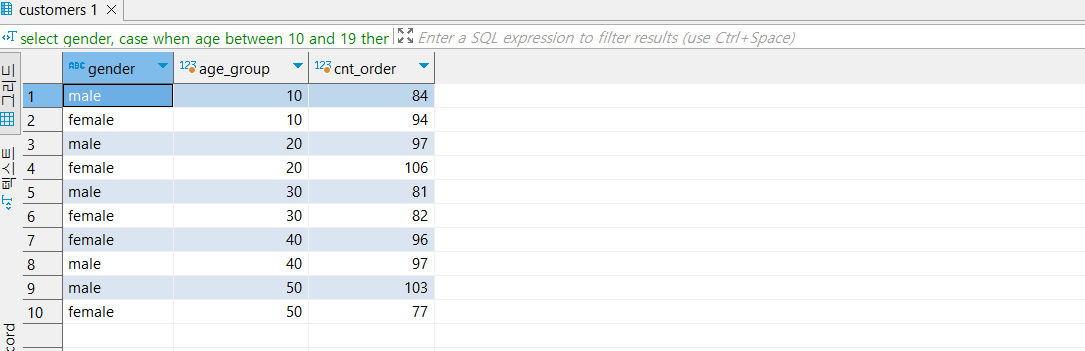
*결과 : 맞음

[2] 연령대가 아닌 연령을 바로 범위화 시켜줬을 때 : 연령대에 따른 총 주문량의 개수를 찾아야 하기에 10대의 총 주문량의 총합을 출력해줘야 하는데, 10대 주문량 중에서 최대인 주문량을 뽑아서 반환(=MAX)해주고 있어서 결과값이 틀리다.
*메인 쿼리문

*결과 : 틀림

*여기서 알 수 있는 것! 아주 중요! 피벗 테이블을 만들 때 max 함수를 사용하는데 그전에 서브 쿼리문에서 한번 segmentation 을 해줘서 유일한 값을 만들어야 깔!끔!하게 피벗 테이블을 만들 수 있다.
[4] 업무 시간 단축 방법
- 윈도우 함수 : 순위를 매기는 것, 누적 함수를 구하는 법 (의미에 집중해 주세요!)
- 행을 단위로 묶어주어서 단위 안에서 연산을 쉽게 하도록 도와준다.
- 많은 기능들이 있지만 이번엔 순위를 매기고, 누적 합을 구하는 두 개만 실습한다.
- 실습 a. N번 째까지의 대상을 조회하는 방법. (RANK)
- 음식 타입별로 주문 건수가 가장 많은 상점 3개씩(금은동) 조회하기
- 베이스 데이터 (음식타입별 음식점별 주문건수) 집계 > rank 함수 적용 > 3위까지 조회하는 순서로 진행한다.

*rank(공백) over (partition by cuisine_type order by cnt_order desc) ranking
: cuisine_type별로 partition을 나눠서 rank over 시킬건데 order건수가 많은(desc) 것부터 1위 시켜주라는 의미이다.
*where 절은 항상 마지막에 사용한다는 것을 잊지 말자.
Q. 근데 왜 over 다음에 스페이스로 띄우는 거야? 값은 같은데 거슬린다.
- 실습 b. 전체에서 차지하는 비율, 누적합을 구하는 방법. (SUM)
- 문제 : 각 음식점의 주문건이 해당 음식 타입에서 차지하는 비율을 구하고, 주문건이 낮은 순으로 정렬했을 때 누적 합 구하기
- 순서 : 음식 타입별, 음식점별 주문 건수 집계 > 카테고리 별 합과 누적합 구하기 > 각 음식점이 차지하는 비율 구하기 > 음식점별 주문건수 오름차순 정렬
Q. (1) 비율 구하라는데 음식 타입의 합계를 구한대 말이 됨?, (2) 정렬하고 누적합 구하는 건 이해했음.
A. 마지막에 전체에서 차지하는 비율 계산가능함. cnt_order(주문건수) ÷ sum_cuisine(총합건수)
[1] 카테고리별 합계 구할 때, group by 안 쓰고도 구하는 방법 : sum에 대한 윈도우 함수 + over
sum(어떤 값을 더하고 싶은지) over (partition by 덩어리 구별 기준) 별칭작성
[2] 누적합 구하는 방법 : order by의 차이임. 순차적으로 내려와 더해주니까.
sum(더하고 싶은 값) over (partition by 덩어리 구별 기준 order by 정렬기준) 별칭작성
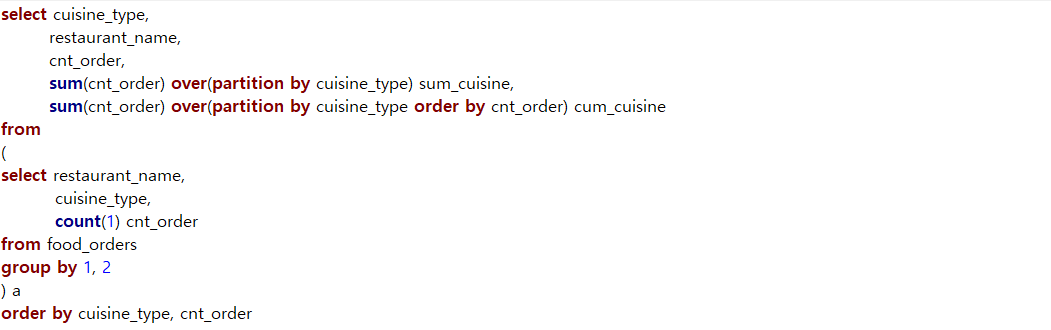

*주문건수가 동일하게 1으로 시작해서 우열을 가릴 수 없으니까 시스템 상 같게 취급해서 9부터 시작한다.
- 실습 c. 날짜 형식으로 바꿔주고 연산으로 손쉽게 데이터 추출이 가능하다.
*메인 쿼리문 : date 컬럼명이고, date함수명(date컬럼명)이다.

*결과 : date 함수는 문자 데이터를 날짜 데이터로 바뀌준다.

- 실습 c-1. 날짜 데이터를 바탕으로 각각의 문자 데이터 추출하기
select date_type,
년,
월,
일,
case when 요일='0' then '일요일'
when 요일='1' then '월요일'
when 요일='2' then '화요일'
when 요일='3' then '수요일'
when 요일='4' then '목요일'
when 요일='5' then '금요일'
when 요일='6' then '토요일' end "요일"
from
(
select date(date) date_type,
date_format(date(date), '%Y') "년",
date_format(date(date), '%m') "월",
date_format(date(date), '%d') "일",
date_format(date(date), '%w') "요일"
from payments
) a
order by 1
*0요일은 일요일, 1요일은 월요일, 2요일은 화요일로 추출되어서 정리해 봄😉
*date_format : 데이트 타입의 컬럼을 포맷팅(=형식을 지정) 해준다.

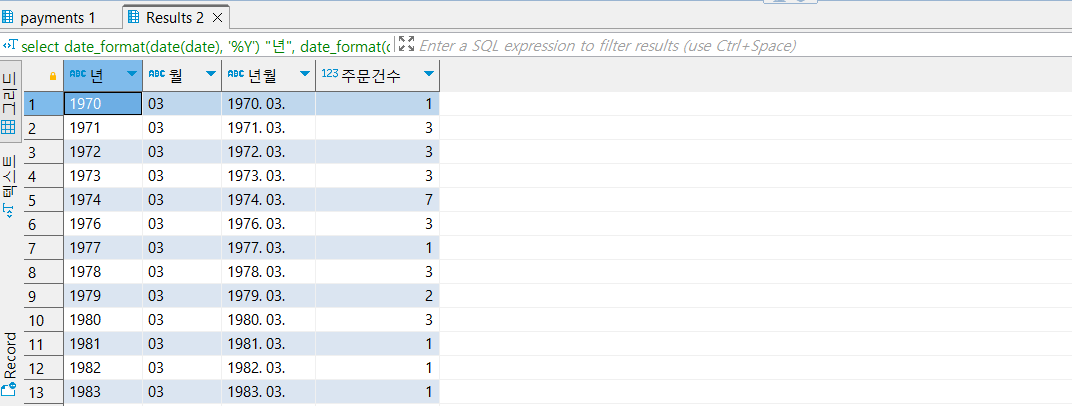
- 실습 c-2. 년도별 3월의 주문 건수 구하기
select date_format(date(date), '%Y') "년",
date_format(date(date), '%m') "월",
date_format(date(date), '%Y. %m.') "년월",
count(1) "주문건수"
from food_orders f inner join payments p on f.order_id=p.order_id
where date_format(date(date), '%m')='03'
group by 1, 2, 3
order by 1
*연월 붙여서 포맷팅할 때, '%Y%m' 이게 기본형이고 위처럼 변형해도 출력 잘 된다.
[5] 5주차 마지막 실습 과제
select cuisine_type,
max(if(age=10, cnt_order, 0)) "10대",
max(if(age=20, cnt_order, 0)) "20대",
max(if(age=30, cnt_order, 0)) "30대",
max(if(age=40, cnt_order, 0)) "40대",
max(if(age=50, cnt_order, 0)) "50대"
from
(
select cuisine_type,
case when age between 10 and 19 then 10
when age between 20 and 29 then 20
when age between 30 and 39 then 30
when age between 40 and 49 then 40
when age between 50 and 59 then 50 end age,
count(1) cnt_order
from food_orders f inner join customers c on f.customer_id=c.customer_id
where age between 10 and 59 <-1세부터 줘서 틀림;;
group by 1, 2 <- 여기서 그룹 1만 줘서 틀림 대실수다
) a
group by 1

좋았던 점
- 아티클 스터디를 통해 데이터 시각화의 중요성에 대해 인지하게 된 계기가 되었음.
- 현존하는 다양한 데이터 시각화 자료를 만나보고 정리해야할 필요성을 느끼게 됨.
아쉬운 점
- group by 유념하면서 코드를 작성하자!
- 뭐야 데이터 값의 업데이트가 느린거야 뭐야 과제 값도 달라
잊지말 점
- 내부 괄호 쓸 때, 열고 바로 닫아준 다음에 가운에 내용을 써주면 괄호 닫는 걸 잊지 않을 수 있음.
- 아무리 복잡한 쿼리문이라도 5가지 SQL 기본구조 순서대로 시작된다.
- 그 다음은 베이스 데이터(유일값)을 만들어야지 MAX를 활용한 Pivot 뷰 작성이 가능하다.
시도할 점
- 수요일 : 데분 강의 1주차
'회고 > TIL(매일)' 카테고리의 다른 글
| TIL 11일차 : Colab, python, pandas, matplotlib, numpy, seaborn (0) | 2023.12.14 |
|---|---|
| TIL 10일차 : correlation (0) | 2023.12.13 |
| TIL 8일차 : 복습, subquery, join (0) | 2023.12.11 |
| TIL 7일차 : if, case when, cast (1) | 2023.12.08 |
| TIL 6일차 : 실습 (1) | 2023.12.07 |